本文共 814 字,大约阅读时间需要 2 分钟。
改进点(跟Funk-SVD比):
一句话总结:SVD++算法在Bias-SVD算法上进一步做了增强,考虑用户的隐式反馈。也就是在Pu上,添加用户的偏好信息。
主要思想:
引入了隐式反馈和用户属性的信息,相当于引入了额外的信息源,这样可以从侧面反映用户的偏好,而且能够解决因显式评分行为较少导致的冷启动问题。
目标函数:
先说隐式反馈怎么加入,方法是:除了假设评分矩阵中的物品有一个隐因子向量外,用户有过行为的物品集合也都有一个隐因子向量,维度是一样的。把用户操作过的物品隐因子向量加起来,用来表达用户的兴趣偏好。
类似的,用户属性如社会学统计信息,全都转换成 0-1 型的特征后,对每一个特征也假设都存在一个同样维度的隐因子向量,一个用户的所有属性对应的隐因子向量相加,也代表了他的一些偏好。
综合两者,SVD++ 的目标函数中,只需要把推荐分数预测部分稍作修改,原来的用户向量那部分增加了隐式反馈向量和用户属性向量:
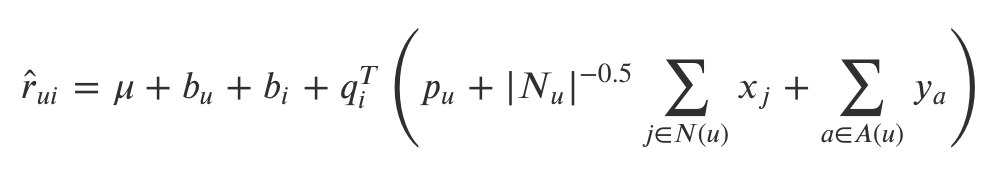
目标函数是:

其中 𝑁(𝑢) 为用户 𝑢 所产生行为的物品集合,|𝑁𝑢|−0.5 是一个规范化(normalization)因子,对总和规范化可带来不错的效果;𝑥𝑗 为隐藏的、对于商品 𝑗 的个人喜好偏置(相当于每种产生行为的商品都有一个偏好 𝑥𝑗),是一个我们所要学习的参数。并且 𝑥𝑗 是一个向量,维度数等于隐因子维度数,每个分量代表对该商品的某一隐因子成分的偏好程度,也就是说对 𝑥𝑗 求和实际上是将所有产生行为的商品对应的隐因子分量值进行分别求和,最后得到的求和后的向量,相当于是用户对这些隐因子的偏好程度;𝐴(𝑢) 为用户 𝑢 的属性集合,𝑦𝑎 与 𝑥𝑗 类似,即每个属性都对应一个隐因子向量,也是要学习的参数。
SVD++整体的优化学习算法依然不变,只是要学习的参数多了两个向量:x 和 y,一个是隐式反馈的物品向量,另一个用户属性的向量。
参考:
1.
转载地址:http://svxwn.baihongyu.com/